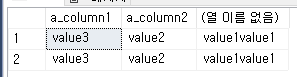
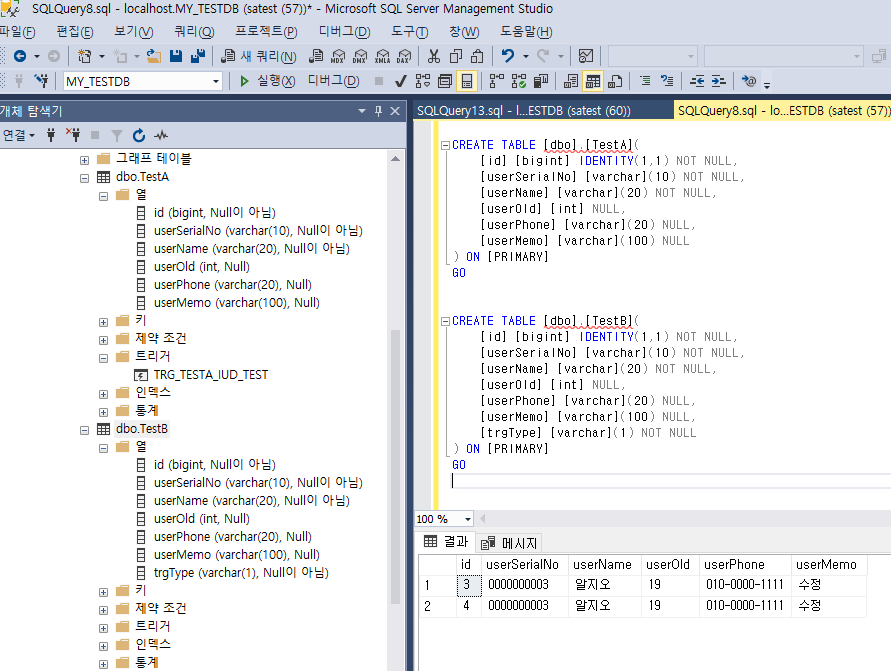
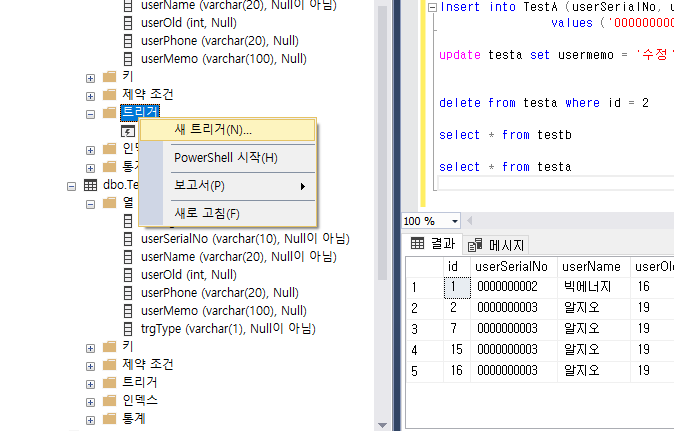
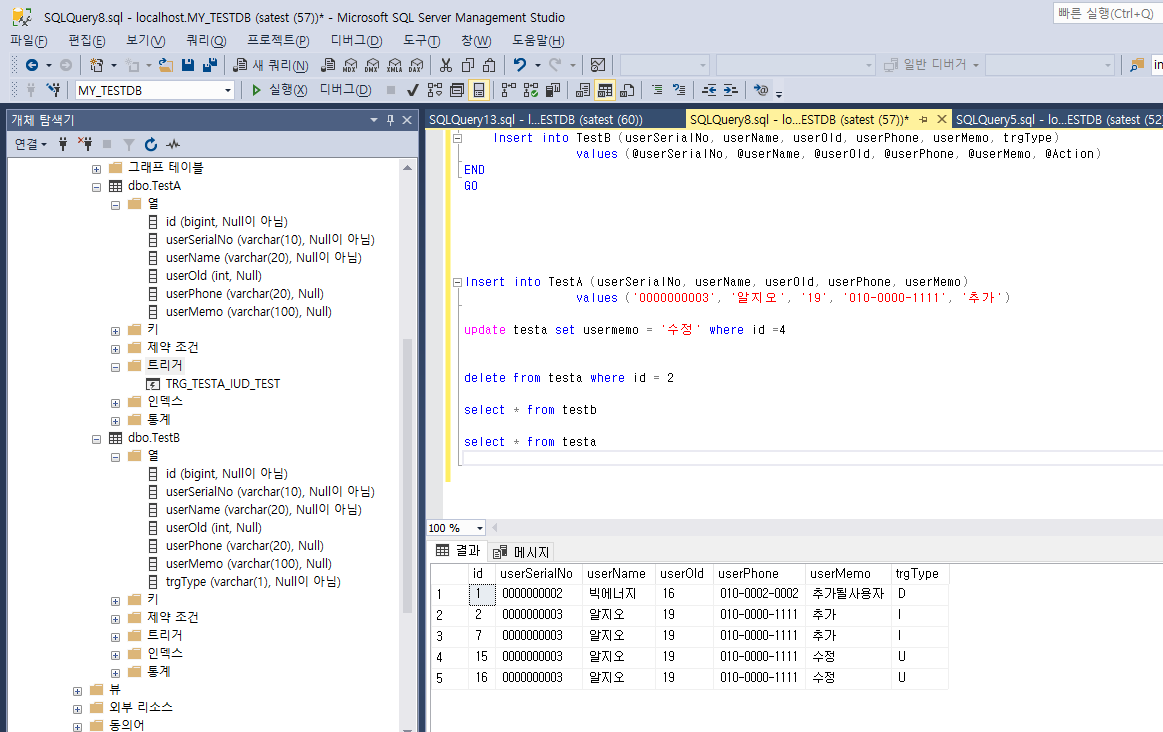
출처 : https://coding-today.tistory.com/123
Vue-CLI Project 기본 구조
vue-cli로 생성된 Project의 기본 디렉터리 구조 파악*자세한 설명 생략 ▷ vue-cli Project 기본 구조 ▷ 관련 글 Vue3 기초 예제 프로젝트 정리Vue3 기초 예제 프로젝트 구조 및 소스 중간 정리 *관
coding-today.tistory.com
vue-cli로 생성된 Project의 기본 디렉터리 구조 파악
*자세한 설명 생략
▷ vue-cli Project 기본 구조

--------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------
--------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------
--------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------
출처 : https://wildeveloperetrain.tistory.com/161
Vue.js 프로젝트 기본 구조에 대한 이해
Vue.js에 대한 공부를 시작하면서 가장 기본이 되는 프로젝트의 구조와 각각의 부분에 대한 이해를 하기 위해 정리한 내용입니다. 잘못된 부분은 댓글로 남겨주시면 확인하고 공부하면서 다시 수
wildeveloperetrain.tistory.com
Vue.js 프로젝트 구조
Vue.js에 대한 공부를 시작하면서 가장 기본이 되는 프로젝트의 구조와 각각의 부분에 대한 이해를 하기 위해 정리한 내용입니다.
잘못된 부분은 댓글로 남겨주시면 확인하고 공부하면서 다시 수정하겠습니다. 미리 감사드립니다.

Vue 프로젝트 구조
'Vue 3'를 기본으로 'vuex'와 'router'를 사용하는 프로젝트를 생성한 결과입니다.
package.json, package-lock.json, node_modules
먼저 package.json, package-lock.json, node_modules 폴더에 대해서 살펴보겠습니다.
package.json 파일은 프로젝트에 대한 정보를 담고 있는데요.
프로젝트의 이름, 버전, private 여부, 배포 및 개발에서 사용할 모듈 정보, 실행 명령어, 지원할 브라우저에 대한 설정 등을 포함하고 있습니다.
dependencies로 설정된 부분이 배포만에서 사용될 모듈이며, devDependencies로 설정된 부분이 개발에서도 사용되는 모듈입니다.
여기서 사용되는 모듈들도 결국 오픈소스 모듈들인데, 해당 모듈들이 동작을 하기 위해서는 또 다른 모듈들을 필요로 합니다.
즉, 모듈들이 동작하기 위해 필요로 하는 모듈들이 있는데 해당 정보가 package-lock.json 파일에 나와있습니다.
그리고 여기에 해당되는 모든 모듈들이 실제로 설치된 곳이 바로 node_modules 폴더가 됩니다.
(package.json에 종속된 라이브러리들이 모여있는 디렉터리입니다.)
/src
/src 디렉터리는 어플리케이션 디렉터리라고도 불리며, 실제 대부분의 코딩이 이루어지는 곳입니다.
바로 이어서 /src 하위 경로를 살펴보겠습니다.
App.vue, main.js, index.html
vue 동작에서의 가장 핵심이 되는 부분인 것 같습니다.
먼저 main.js 파일은 npm run serve 명령어를 통해 뷰를 실행시켰을 때, 가장 먼저 실행되는 JavaScript 파일입니다.
Vue 인스턴스를 생성하는 핵심 역할을 하는데요.

main.js
main.js의 코드입니다.
내용을 살펴보면 vue로부터 createApp을 가져옵니다. 그리고 createApp 함수를 통해 App.vue 컴포넌트를 가지고 인스턴스를 만들어서 #app(id="app")에다가 해당 인스턴스를 mount 한다는 것인데요.

index.html
위에서 나온 id="app"가 있는 곳이 바로 index.html입니다. index.html은 어플리케이션의 핵심이 되는 파일인데요.
Vue.js는 싱글 페이지 어플리케이션(Single Page Application)이라는 특징을 가지고 있는데, 싱글 페이지 어플리케이션이라는 것이 바로 index.html 하나만을 가지고 Vue Application을 구동한다는 것입니다.
정리해보면, npm run serve 명령어로 뷰를 실행시키는 순간 main.js 파일이 실행되는데, main.js 파일은 vue를 기반으로 createApp 함수를 실행합니다. 그리고 이때 가장 먼저 가지고 오는 것이 통합 컴포넌트인 App.vue 파일인데요.
이렇게 만들어진 인스턴스를 index.html의 id="app"에다가 mount 하게 되는 것입니다.
App.vue 파일을 하나의 컴포넌트 파일이라고 하는데, App.vue의 경우 내부에 여러 컴포넌트들을 불러와서 main.js로 한 번에 넘겨주는 통합 컴포넌트라고 할 수 있습니다.
Component 파일
컴포넌트 파일은 <template>, <script>, <style> 부분으로 나누어져 있는데요.
template 부분에는 HTML로 화면상에 표시할 요소들을 작성하고, script 부분에는 스크립트 코드를 작성할 수 있습니다. (import와 export가 있습니다.)
style 부분에는 template의 HTML 요소를 꾸며줄 css 구문들을 작성해줄 수 있는데요. scoped 속성을 사용하면 특정 컴포넌트에서만 고유의 스타일을 선언할 수 있습니다.
.vue 확장자를 가진 컴포넌트 파일은 /components 디렉터리에도 있으며, /views 디렉터리에도 있습니다.
두 군데로 나눠지는 차이점은 /views 디렉터리의 경우 화면 전체에 해당하는 컴포넌트를 관리하는 부분이며, 화면 전체가 아니라 부분으로 구성되어 재사용할 수 있는 컴포넌트들을 /components 디렉터리에서 관리하게 되는 것입니다.
router/index.js, /views
App.vue의 <template> 부분을 살펴보면 <router-view/>라는 부분을 볼 수 있는데요.
이 부분이 router/index.js와 연결되어 동작하는 부분입니다.
라우팅이란, 웹 페이지 간의 이동 방법으로 Single Page Application(SPA)에서 주로 사용되는데요.
SPA이란, 페이지를 이동할 때마다 서버에서 웹 페이지를 요청하여 새로 갱신하는 것이 아니라, 사용할 페이지들을 미리 받아놓고, 페이지 이동시에 클라이언트 라우팅을 이용하여 화면을 갱신하는 방법입니다.
router/index.js 파일에는 Object 배열의 routes가 선언되어 있는데요.
각각의 router는 path, name, component 값을 가지고 있는데, name은 유니크 값을 가져야 하며, component라는 키는 path로 접근했을 때 연결할 실제 컴포넌트 파일 이름을 나타냅니다.
(최종적으로 프로젝트 운영에 올라가게 되는 vue component 파일들은 javascript 파일로 컴파일되어 올라가게 됩니다.)
/assets
font, icons, images, css 등, 어플리케이션에서 사용되는 정적 파일이 모여있는 디렉터리입니다.
(/public 디렉터리와는 다르게 webpack의 처리를 받을 수 있다는 특징이 있습니다.)
* 해당 내용은 유튜브 '개발자의품격 - 4시간 만에 완벽하게 끝내는 Vue.js 입문' 영상을 많이 참고한 내용입니다.
(Vue.js 프로젝트를 처음 접하는데 쉽게 잘 설명해주는 영상이었습니다. )